微服務架構下的分布式數據存儲 數據處理和存儲支持服務
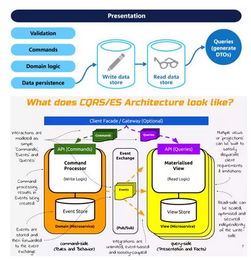
隨著微服務架構的廣泛采用,分布式數據存儲和處理成為實現系統可擴展性、可靠性和靈活性的關鍵。在微服務環境中,每個服務通常擁有獨立的數據存儲,而分布式數據存儲與處理支持服務則提供了一整套解決方案,以應對數據一致性、性能優化和運維復雜性等挑戰。
一、分布式數據存儲的核心特性
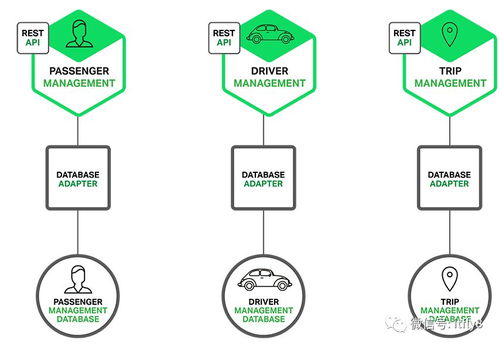
微服務架構下的分布式數據存儲強調數據的分區、復制和容錯能力。通過將數據分散到多個節點,系統能夠實現水平擴展,同時借助副本機制確保高可用性。常見的數據存儲模式包括關系型數據庫的分庫分表、NoSQL數據庫(如MongoDB、Cassandra)以及NewSQL數據庫(如Google Spanner),它們各自適用于不同的業務場景,例如高吞吐量的鍵值存儲或復雜事務支持。
二、數據處理與存儲支持服務的關鍵組件
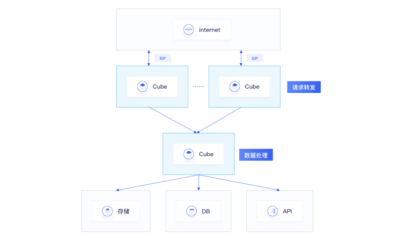
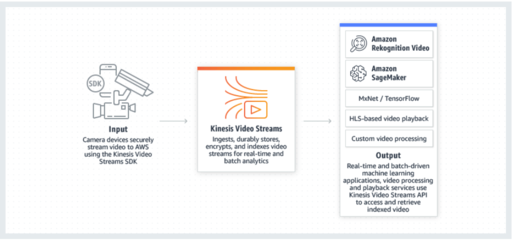
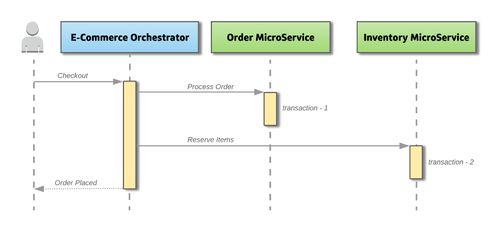
在分布式環境中,數據處理和存儲支持服務通常包括數據分片、復制管理、一致性協議和查詢優化等模塊。例如,數據分片服務負責將數據分布到不同節點,以實現負載均衡;復制服務通過主從或多主復制機制保障數據冗余;而一致性協議(如Raft或Paxos)則確保在分布式事務中的數據原子性和隔離性。緩存層(如Redis)和消息隊列(如Kafka)常被集成,以提升數據處理效率和異步通信能力。
三、面臨的挑戰與解決方案
微服務分布式數據存儲面臨的主要挑戰包括數據一致性、網絡延遲和運維復雜度。為了解決這些問題,業界提出了多種策略:采用最終一致性模型以平衡性能與一致性要求;使用服務網格(如Istio)來管理服務間通信,減少延遲;并借助自動化工具(如Kubernetes)進行動態擴縮容和故障恢復。數據治理和監控服務(如Prometheus)幫助跟蹤數據流和存儲狀態,確保系統穩定性。
四、實際應用與未來趨勢
在實際應用中,企業通過組合多種數據存儲技術來滿足不同微服務的需求,例如將事務性數據存儲在關系數據庫中,而將日志或用戶行為數據存入NoSQL系統。隨著云原生和邊緣計算的發展,分布式數據存儲將更加注重跨區域數據同步、智能數據分區以及AI驅動的自動化管理,以支持更復雜的微服務生態系統。
微服務架構下的分布式數據存儲與處理支持服務是構建現代化應用的基礎。通過合理的架構設計和工具選擇,企業可以充分發揮微服務的優勢,實現高效、可靠的數據管理。
如若轉載,請注明出處:http://m.iwuf.org.cn/product/7.html
更新時間:2026-01-07 09:45:32