構建企業數據運營體系 數據處理與存儲支持服務全解析
在數字化轉型的浪潮中,企業數據運營體系已成為提升核心競爭力的關鍵。一個完善的數據運營體系不僅能夠驅動業務增長,還能優化決策流程、降低運營成本。本文將深入探討構建企業數據運營體系的核心環節——數據處理和存儲支持服務,為您提供可操作的實施指南。
一、數據運營體系的基礎框架
企業數據運營體系是一個系統工程,涵蓋數據采集、處理、存儲、分析和應用等多個維度。其中,數據處理和存儲作為體系的基石,決定了數據質量和可用性。缺乏高效的數據處理與存儲支持,即使擁有海量數據,也難以轉化為業務價值。
二、數據處理:從原始數據到可用資產
數據處理是數據運營的核心環節,主要包括數據清洗、整合、轉換和加工。
- 數據清洗與標準化:原始數據往往存在重復、缺失或格式不一致等問題。通過自動化工具和規則引擎,對數據進行去重、補全和格式統一,確保數據質量。例如,利用ETL(提取、轉換、加載)工具,將多源數據轉換為標準格式。
- 數據整合與關聯:企業數據通常分散在不同系統中(如CRM、ERP、日志系統等)。通過數據整合技術,打破數據孤島,建立統一的數據視圖。例如,通過主數據管理(MDM)系統,實現客戶、產品等核心數據的唯一標識和關聯。
- 實時與批量處理:根據業務需求,選擇實時流處理(如Apache Kafka、Flink)或批量處理(如Hadoop、Spark)。實時處理適用于風控、監控等場景,而批量處理更適合報表生成和離線分析。
三、數據存儲:構建可靠的數據倉庫與數據湖
數據存儲不僅關乎數據安全,還影響數據訪問效率和擴展性。企業需根據數據類型和使用場景,設計分層存儲架構。
- 數據倉庫:適用于結構化數據,支持復雜查詢和業務分析。通過維度建模(如星型模型、雪花模型),將數據組織為主題域,便于OLAP(聯機分析處理)。常見工具有Amazon Redshift、Snowflake等。
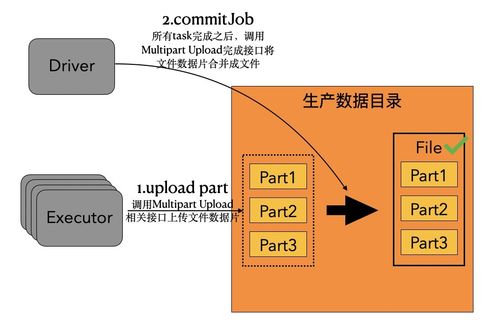
- 數據湖:用于存儲原始和非結構化數據(如圖像、日志文件),支持靈活的數據探索和機器學習。數據湖通常基于HDFS或云存儲(如AWS S3、Azure Blob Storage)構建,并搭配元數據管理工具(如Apache Hive)實現數據目錄。
- 混合存儲策略:結合數據倉庫和數據湖的優勢,構建“湖倉一體”架構。例如,將原始數據存入數據湖,經過處理后加載到數據倉庫,兼顧靈活性和性能。
四、支持服務:保障數據運營的持續運行
數據處理和存儲離不開配套的支持服務,包括數據治理、安全與運維。
- 數據治理:建立數據標準和管控流程,確保數據的準確性、一致性和合規性。通過數據血緣分析、質量監控工具,跟蹤數據生命周期,降低數據風險。
- 數據安全:實施加密、訪問控制和審計機制,保護敏感數據。例如,采用角色權限管理(RBAC)、數據脫敏技術,防止未授權訪問。
- 運維與監控:通過自動化運維平臺,監控數據處理任務的性能和存儲系統的健康狀態。設置告警機制,及時發現并解決故障,確保服務高可用。
五、實施路徑與最佳實踐
構建數據處理和存儲體系需分步推進:
- 階段一:需求分析:明確業務目標,評估現有數據資產和技術棧。
- 階段二:架構設計:選擇適合的存儲方案(如云原生或混合部署),設計數據處理流水線。
- 階段三:工具選型與實施:根據預算和團隊能力,選用開源或商業工具(如Apache NiFi用于數據流管理,MySQL或MongoDB用于存儲)。
- 階段四:迭代優化:通過監控和反饋,持續優化數據處理效率與存儲成本。
結語
數據處理和存儲支持服務是企業數據運營體系的命脈。通過構建高效、安全的數據管道與存儲架構,企業能夠釋放數據潛力,實現智能決策與業務創新。本文提供的框架與實操建議,可作為企業數據戰略的參考,助您在數據驅動時代占得先機。
(本文為干貨長文,建議收藏以備后續查閱。)
如若轉載,請注明出處:http://m.iwuf.org.cn/product/12.html
更新時間:2026-01-07 00:48:09